

Last week we’ve discussed some of the problems related to our current iteration of the internet. It was pretty doom and gloom, but now we’ll discuss what IPFS will do to solve those problems, and thus, let us see the light at the end of the internet tunnel.
As a quick recap, here are the four problems we’ve identified with the internet last week: 1. its shaky security 2. its inefficiency in supplying increasing demand from users 3. it’s crippling centralisation 4. its proneness to censorship.
We will discuss security and efficiency. Let’s dive in!
Security: No Need to Trust Anyone
IPFS promises a secure internet by removing the necessity of trusting the honesty of a third-party. As such, all IPFS data is self-certifying, which simply means that the user is able to determine by himself that the data he receives is trustworthy.
The secret to this self-certification comes from the power of hashing functions. Hashing functions are special mathematical entities which, if inputted data, will output a unique fingerprint called the hash.
And by unique, we truly mean unique.
Theses functions are engineered in such a manner that it is so ridiculously improbable to find two pieces of data producing the same result, that it becomes in practice impossible to produce a forgery of the initial data.
The hash is to data what a fingerprint is to a human. It uniquely identifies an individual. However, we cannot reconstruct a person from a fingerprint. This means that the hash is a unique identifier that does not compromise the privacy of the original data. One cannot reproduce the data from the hash alone.
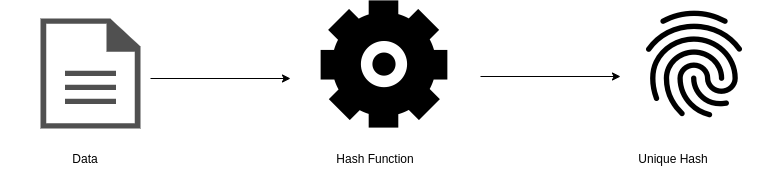
Okay, so there’s this computer sciency math stuff… but what does it have to do with IPFS?
In HTTP, when the user, let’s say, goes to codeclimbing.com (a blog I highly recommend!! :D), the browser fetches the data at the LOCATION of the server of codeclimbing.com. This location can be spoofed by hackers. Maybe one can intercept the request and instead of sending the blog, he sends a phishing website trying to get a user’s password…
But with IPFS, the users will not ask for codeclimbing.com, but instead for a hash which looks something like this: QmTkzDwWqPbnAh5YiV5VwcTLnGdwSNsNTn2aDxdXBFca7D.
Supposing a hacker intercepted the request for QmTkzDwWqPbnAh5YiV5VwcTLnGdwSNsNTn2aDxdXBFca7D and tried to send a malicious phishing site, the user could run the received data through a hashing function, compare the hash of the received data with the requested hash, and reject the incoming data on the basis that the hashes do not match.
The evil hacker’s plan has been thwarted!
The consequences of such a scheme are immense. Data integrity is ALWAYS preserved.
If a user requests a legal document, not a single letter of that document will be different. If a user downloads a program, not a single 1 or a single 0 will differ. If the user requests a picture, every pixel will be at the exact same location, an interesting property in a time of deep fakes, where the authenticity of a picture can be difficult to ascertain.
This focus on using hashing functions to fetch data is called CONTENT addressing (because the content is hashed) as opposed to the aforementioned LOCATION addressing. I think you’ll agree, it’s way more secure that way.
That being said, there’s another important property that content addressing unlocks. And it’s…
Efficiency & Speed: The Digital Lamborghini
There’s something missing from the explanation above which you might have already picked up on if you were exceptionally astute: since users ask for data based on the hash of its content instead of its location, how do we know where to find this data at all? Where IS the data? In which server exactly?
The answer is that the data can be anywhere. IPFS is a peer-to-peer network in which ANYONE can contribute. You can think of it like BitTorrent, the protocol often used to distribute pirated movies and songs.
And since anyone can distribute data, a user in the US, for example, doesn’t have to ask data to a faraway server in China, he can simply take this data from someone else near his geographical location, and vice-versa for the other way around. This is much more efficient, especially if the data is right next to the user, geographically speaking.
Suppose there is a room filled with 100 HTTP users and 100 IPFS users and they all want to go to codeclimbing.com (because it’s such a great blog! :D), how will their experiences differ?
The 100 HTTP users will make a request to the LOCATION of codeclimbing.com. Each of those requests, will go through the internet, bounce through a bunch of routers, until finally arriving at a server which is, in all probability, from Google and 1000s of kilometers away, the requested data is then sent from the server, bouncing back through a bunch of routers again, to finally arrive in the user’s hands.
What does the request look like, from the point of view of the IPFS users? The 100 IPFS users make a request to the IPFS network for the hash of the data. What if someone in the room has the file? Why bother going through routers and to a potentially remote server? That geographically near user can share it with another user and that user can share it with another one, and another one.
Content addressing is clearly much more efficient location addressing in this case! And of course, it’s all done in secure manner.
On the Next Episode of….
It is possible to keep going deeper with those topics, but we will keep it at that for now. Hopefully, you had a good taste of what the distributed internet has to offer!
Come back next week and we will continue this discussion about how IPFS will solve two other problems of the Internet: centralisation and proneness to censorship.
감사합니다.
Glad it was useful to you!