

This is the second and last part in a discussion of how IPFS plans to fix the internet’s biggest problems.
In the previous part, we’ve discussed how IFPS makes the web more secure and efficient.
This week we’ll discuss how IPFS addresses concerns with centralisation and censorship on the internet.
Decentralisation: An Actual Web for the Web
As the saying goes, do not put your eggs in the same basket! Sadly, that is exactly how the modern internet is organised. All the eggs, the data, are stored in these massive baskets, the servers, to which clients must connect to.
This arrangement makes the system fragile, as a problem with the server means clients cannot access anything at all. It also means that, if there is a sudden influx of egg hungry connoisseur, the basket will not have enough throughput to feed everyone. We can imagine a long line of people waiting to be fed, each having to wait for the one in front to pluck his own egg.
The secret, therefore, for IPFS is simply to not put the eggs in the same basket! In fact, eggs are spread over a distributed network of baskets.
But enough with the eggs… long story short, IPFS is distributed network. As such, it falls in the line of other peer-to-peer protocols such as BitTorrent.
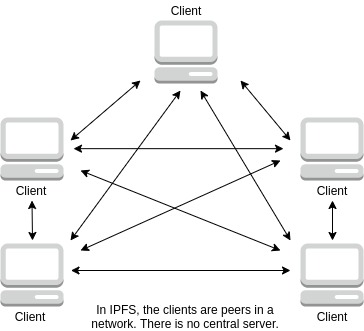
This has an important consequences. Since the network doesn’t depend on a single server, computers can go online and offline and the network will still function.
Think about a scenario in which we want to connect to Facebook, but the servers are down. We can’t connect, since connection depends on the server being available.
On the other hand, let’s imagine an IPFS-based version of Facebook. The data could live with some sort of encryption scheme on IPFS where the user possesses the keys to access his private data and is free to access other users’ public data. In that case, there is NO WAY to prevent a user from connecting to the site and accessing his data. In effect, if a peer goes offline, there is another one that can possess the data.
That’s an amazing property that is only possible with IPFS.
Similarly, if a large amount of users want to access the same file in our current version of the web, it would cause a massive demand surge that might possibly strain a server to exhaustion. But in IPFS, the file can be shared peer-to-peer. Once a peer has a file, he can share it to another peer, and another.
The file will always be accessible even under high demand!
This is just like BitTorrent where popular files are made MORE accessible instead of LESS by virtue of the file’s data being shared among peers.
Speaking of BitTorrent, this leads us to the next point…
Censorship Resistance: True Freedom of Information
We mentioned BitTorrent earlier. Isn’t it amazing that authorities were never able to shut it down, despite the breaches to the law through copyright infringement from distributing pirated movies, shows, songs and games?
No matter how hard governments try they cannot stop this soup of illegal activity that is BitTorrent.
Such is the power of a distributed network!
Since there is no central server to shutdown, authorities have no individual entity to attack. Everyone is a peer! So if one is stopped, there is another peer to replace it. And to attack everyone is, quite simply, unfeasible.
Of course, this means that IPFS could become a safe haven of illegal activities. There has been ideas brought forward to curb this negative side-effect of a distributed network of files, such as lists of blacklisted hashes. I personally doubt these solutions will have any effect. For instance, if someone were to blacklist the hash of an illegal file, what would stop someone from simply changing a pixel and, thus, the hash?
There could be an infinite amount of illegal hashes produced, making a blacklist list unrealistic.
Despite that, IPFS brings an important benefit: censorship resistance.
Since bad files cannot be stopped, neither can the good ones! It is open to interpretation whether this property will have a good or bad effects. Whether disinformation will drown out good information. Whether lies will bury truth.
My personal belief on this matter is that good ideas have a tendency to rise. Complete truth will never emerge from a purely distributed network yet, in average, there will be more good than bad. Not to mention that centralised systems have failed to kill off bad ideas. So why not favour uncensorable systems instead, and let users themselves sort through the data?
Also, certain innovations might work in conjunction with IPFS to certify the truth about a piece of data. What if we saved important IPFS hashes to a blockchain system such as Ethereum? This will mean that the hash will also be associated with a truthful and unchangeable timestamp. We can associate an uncensorable file in a verifiable moment in time.
Let me explain why I find this exciting. We are talking a lot about deep fakes these days. Malicious individuals, and maybe even governments and agencies, modify pictures and videos in such manners to distort reality. Faced with an avalanche of contradictory images and videos, the truth becomes increasingly difficult to ascertain… but what if we had a timestamped hash of a file of the original picture or video? Suddenly, we can disprove any modified version of this file done AFTER the timestamp!
This should lead to greater access to verifiable truths.
But only time will tell whether I will end up being right or not about this.
And the Time that is coming, how exciting it will be!